
[image: image.png]
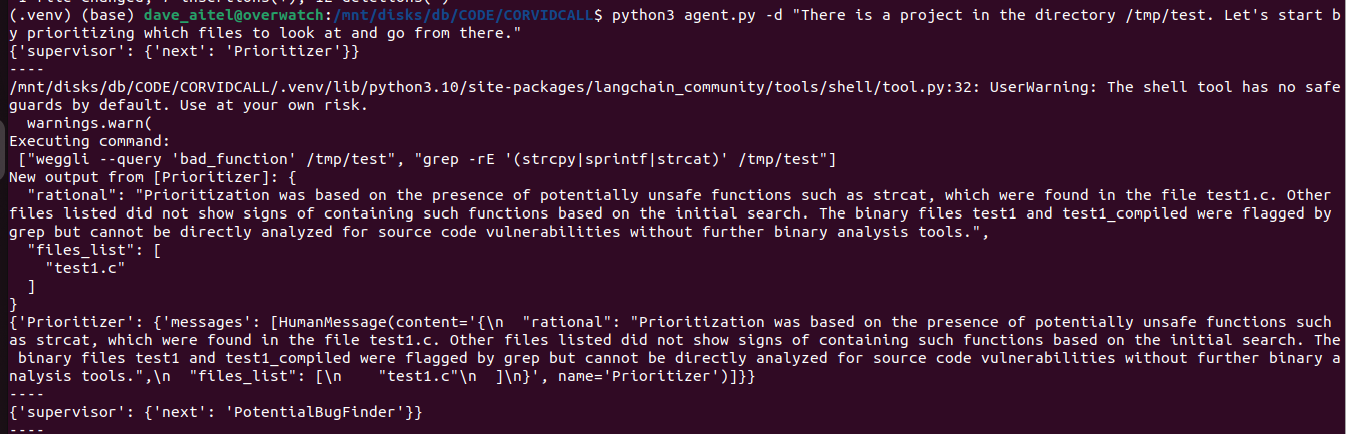
Like everyone I know, I've been spending a lot of time neck deep in LLMs. As released, they are fascinating and useless toys. I feel like actually using an LLM to do anything real is your basic nightmare still. At the very minimum, you need structured output, and OpenAI has led the way in offering a JSON-based calling format which allows you to extend it with functions that cover the things an LLM can't really do (i.e. math, or access the web or your bash shell). In real life you are going to use this through LangChain or some similar library.
You can do this sort of thing with Claude (a better model than GPT-4 in many respects for code), but it's janky as the model wasn't specifically fine tuned for this purpose yet. Your best bet, as you see everyone do, is to force it to start its reply with a curly bracket "{", but even then it's going to pontificate about its reply after it sends you the JSON object you want, if you're lucky and it uses your format at all.
Claude is more based on XML than JSON, which, if you think about how LLMs work, makes a ton of sense. To an LLM, {' may be one token, or {{{{ may be a token. In fact, let's test that:
import tiktoken encoding = tiktoken.encoding_for_model("gpt-4") encoding.encode("{")
[90]
encoding.encode("{{")
[3052]
encoding.encode("{{{")
[91791] #one token
encoding.encode("{{{{")
[3052, 3052] #two tokens
encoding.encode("{{{{{")
[3052, 91791] #two tokens
encoding.encode("{{{{{{")
[3052, 3052, 3052] #three tokens
encoding.encode("{'")
[13922] #{ ' is one token
Yeah, so like, on one hand, that's great. Very optimized compression on token lengths. But on the other hand, it is very confusing for the model to train on and understand! You can see why XML would be much more natural! < SOME WORD > is more likely to be three tokens, which makes creating clean output much easier. Claude's focus on XML probably makes it "smarter" in some ways that are hard to prove with math.
encoding.encode("<high>")
[10174, 1108, 29]
encoding.encode("<html>")
[14063, 29]
encoding.encode("</html>")
[524, 1580, 29]
encoding.encode("/html")
[14056]
encoding.encode("</high>")
[524, 12156, 29]
encoding.encode("high")
[12156]
Also, of course, I highly recommend Halvar's latest talk (which is highly relevant): https://www.youtube.com/watch?v=xA-ns0zi0k0&t=4s
-dave
{kind=link}
dailydave@lists.aitelfoundation.org
-
 Dave Aitel
Dave Aitel